
Expert Consulations
Finding the perfect balance between business goals, engaged users and technical performance
Getting a succesfull app is not just about having the right idea or using expert developers to build the app. TPA will assist you in the entire process and help you achieve your goals.
Finding the perfect balance between business goals, engaged users and technical performance

Advanced analytics on user behaviour and stability

Test app distribution, crash handling, live app analytics and more
In order to achieve success with your app, you need to focus on all of the following aspects:
Read on below
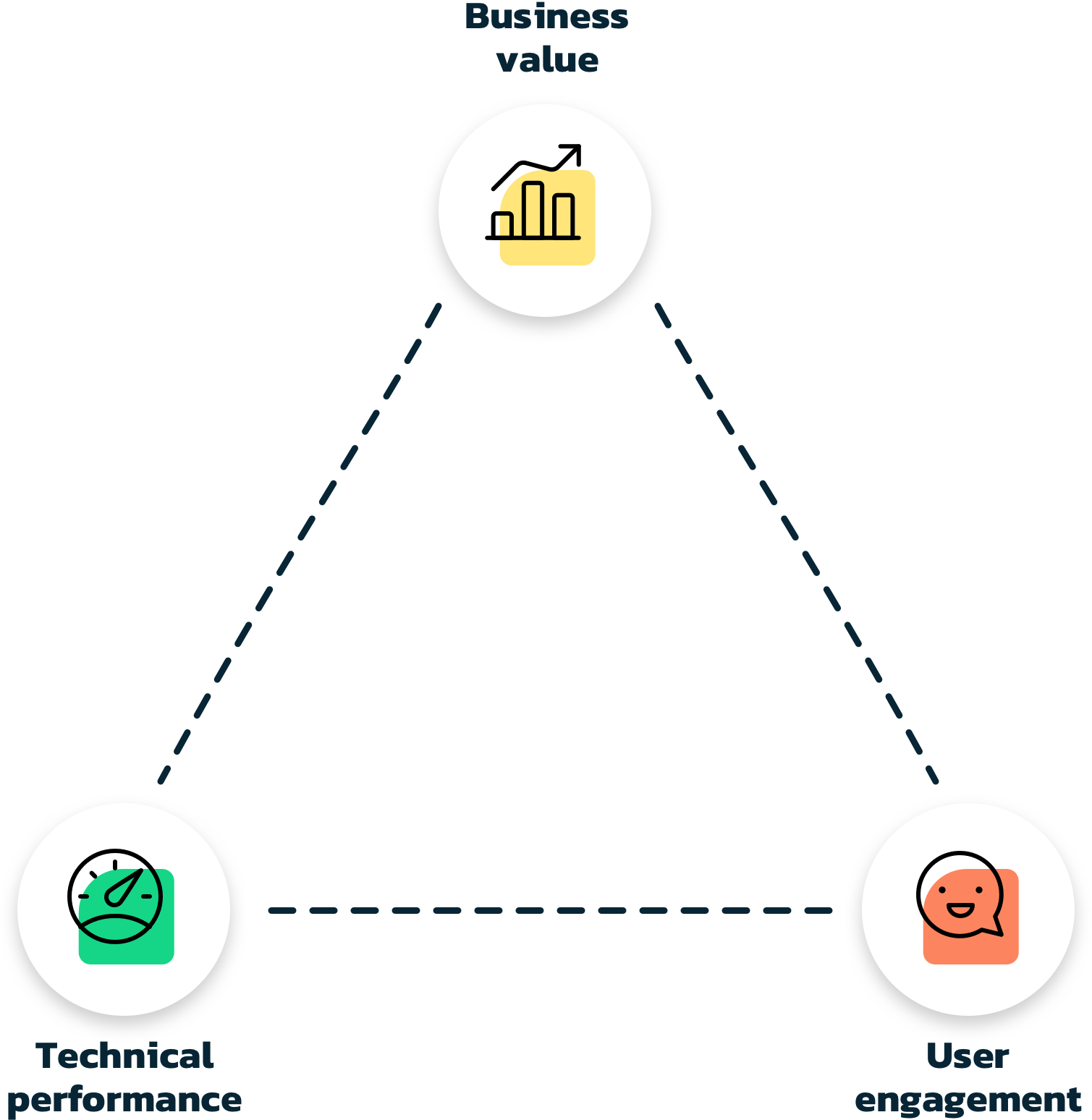
Any investment must bring some sort of value to your business. The value can be anything from gaining more customers, company branding, selling more products etc. Measuring if purchases is made through an app is easy, but evaluating company branding impact and determining if an app can help bring customers to your business can be a difficult task.
Making an app is often a big investment and how to gain business value must be considered from the beginning to ensure a long lasting app success.
Engaged users are critical to obtaining business value. Building an app that is great for selling your services may not entice users to spend time in it. If users do not get value from your app, they may easily stop tapping that beautiful icon on their phone.
In order for an app to be succesful, you need to provide value to the user. Give the users an experience that makes them want to come back to your app instead of the one next to it.
Even the most compelling app will have a hard time retaining your users, if it does not perform. Crashes, long loading times, incorrect results will drive users away, perhaps even with a bad review publicly available for anyone to read. This will definitely not bring you engaged users and business value.
Getting optimal performance in your app requires experienced developers and thorough testing. But the technical performance does not only apply to the app itself. Any backend integrations need to be optimized for slow network connections and have proper error handling to provide the user with relevant feedback.
Obtaining the perfect app is about reaching a balance between technical performance, user engagement and business value. Spending enough money will make it possible to achieve technical performance and user engagement, but may give you a hard time reaching your business value goals.
Let us help you find the perfect balance for your business.
From the first build to a running app in the AppStore - the TPA Tools will help you manage your apps and achieve your goals.

Advanced app management that will handle anything from a single app to complex setups

Distribute test apps - get feedback. The most important tasks before your ship

Stay on top of issues. Fix them before they become a problem.

Blazing fast live analytics with fully customizable dashboards
Don't hesitate to contact us, if you want to know more about our services or our tools.
For more info contact us